












As AI workloads grow in complexity and scale, choosing the right storage infrastructure has never been more critical. In the “Storage Trends in AI 2025” webinar, experts from SNIA, the SNIA SCSI Trade Association community, and ServeTheHome discussed how established technologies like SAS continue to play a vital role in supporting AI’s evolving demands—particularly in environments where reliability, scalability, and cost-efficiency matter most. The session also covered emerging interfaces like NVMe and CXL, offering a full-spectrum view of what’s next in AI storage. Below is a recap of the audience Q&A, with insights into how SAS and other technologies are rising to meet the AI moment.
Q: Could you explain how tail latency tied to data type?
A: Tail latency is more closely tied to service level agreements (SLAs). In AI platforms, tail latency isn’t typically a key concern when it comes to model calculations.
Q: For smaller customers, what are best practices for mixing Normal Workloads (like regular VM Infra) with AI workloads? Do they need to separate those workloads on different storage solutions?
A: There are no "small customers," there are only "small workloads." You right-size the bandwidth and server memory/storage for the workload. The trade-off has to do with time, because if you're creating a negotiation for resources and utilization then you either must dedicate the resources that you have available or you must accept the extended time necessary for completion.
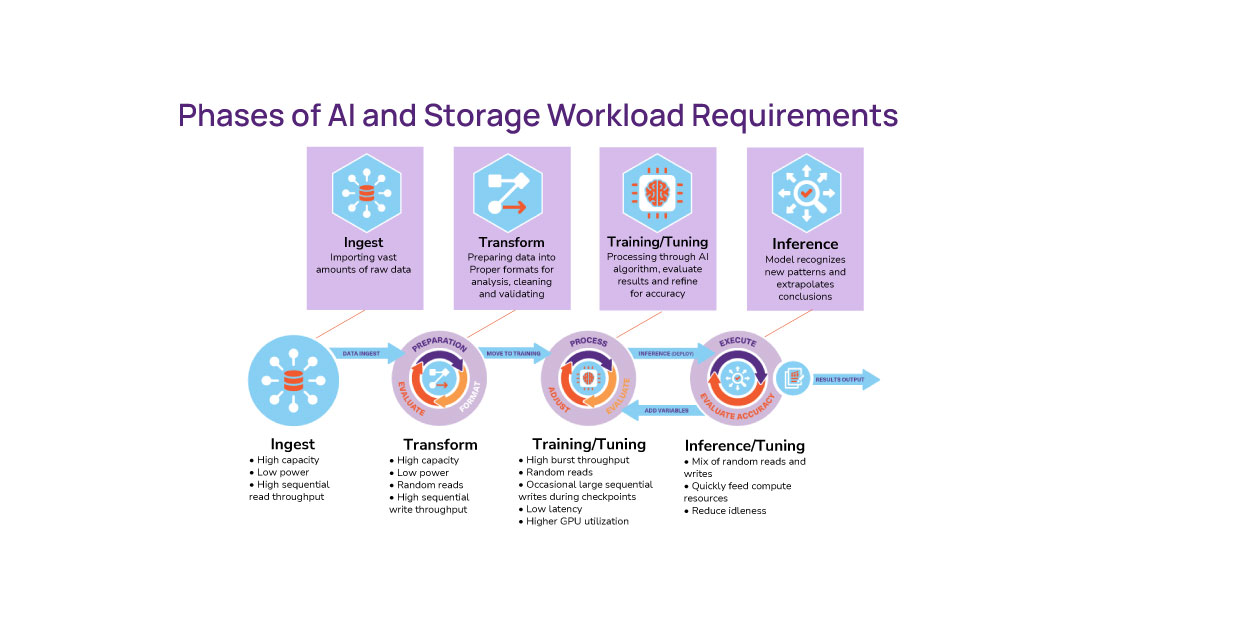
Q: Storage technology is moving towards NVMe and with less focus on spinning drives. How is SAS being used for AI workloads?
A: SAS still plays a critical role in the ingest phase of AI workloads, where large data volumes make it a key enabler.
Q: What are power usage budgets looking like for these workloads?
A: That's an excellent question but unfortunately it is vendor-specific because of the number of variables involved.
Q: Are the AI servers using all the on chip PCIe lanes. Ex: 5th Gen Xeon 80 lane PCIe 5.0 per CPU? I would guess the servers have 4 or 8 CPUs. So 8 x 80 lanes = 640 PCIe lanes per AI server.
A: Short answer is no. No system uses 100% of the lanes for one type of workload. Usually there is a dedicated allocation for specific workloads that is a subset of the total available bandwidth. Efficiency of bandwidth is another challenge that is being tackled by both vendors and industry organizations.
Q: Is your example of GPU / CPU memory transfers a use for CXL?
A: It certainly can be.
Q: Are any of the major storage OEMs using 24G SAS on the back-end?
A: Yes, both Dell and HPE offer AI targeted servers with SAS and NVMe storage options, among other options.
Q: Question for Patrick: There is a group of industry veterans who think smaller, hyper-focused, and hyper-specialized AI models will add more value for enterprises than large, general purpose, ever-hallucinating ChatGPT-style models. What are your thoughts on this? If scenario pans out, wouldn't "AI servers" be overbuilt? The enterprise arrays, along with advancements in Computational Storage, would lean towards all-flash or flash+disk storage setup?
A: As AI gets better, it ends up becoming more useful, and the overall demand goes up. For example, is training and operating humanoid robots a value for a manufacturing enterprise? If so, we do not have the compute to do that at scale yet. Likewise, functions like finance, procurement, and others should eventually all be automated. If we need many specialized smaller models, then they still need to be trained, customized, and inference run on an ongoing basis. Re-training on new data or techniques will continue. New application spaces will open up. Also, (retrieval-augmented generative (RAG) is able to be incorporated in open-source solutions and that cuts down on hallucinations.
Overall, this is an area where, when you think of the scope of what needs to be done to achieve the automation goals, there is nowhere near enough compute for either training or inference. Even once something is automated, then the next question is how a company gets a competitive advantage by doing something better that will require more work. If we look back in 10 years, it is unlikely everything will be solved, but I imagine trying to explain to my son in 15 years how everyone had to drive themselves “back in my day.” There are folks that deny this is going to happen today, but I have also driven either by Waymo or Tesla FSD 30 minutes or more every day I am home for the last six months. The inhibitor to adoption is regulatory at this point.
I think disk is still going to be dominant for lower-cost storage when the main metric is $/PB. Flash is needed to feed the big AI systems, so it is really a question of whether the performance of flash overcomes the price delta. Also, the larger capacity SSDs can save cost not just in terms of $/TB of the media but also in the connectivity costs. computational storage removes the need to move data, and so there is a decent chance we will see that not just in the persistent layer but also in the memory layer.
Q: Where do you see FC in the AI infrastructure?
A: Fibre Channel isn’t particularly relevant to this discussion. It has a role in networking, but it's not specific to AI infrastructure.
Q: Is the interface going to change from 24G SAS to 24G+ SAS? Is 29pin counts still SAS?
A: Both 24G SAS and 24G+ SAS operate on the SAS-4 physical layer, with no changes in the core interface. However, 24G+ SAS introduces new connector options. The existing 24G SAS connectors are fully compatible, and a new internal connector (SFF-TA-1016) has been introduced for 24G+ SAS, which is also backward compatible with 24G SAS.
Leave a Reply