






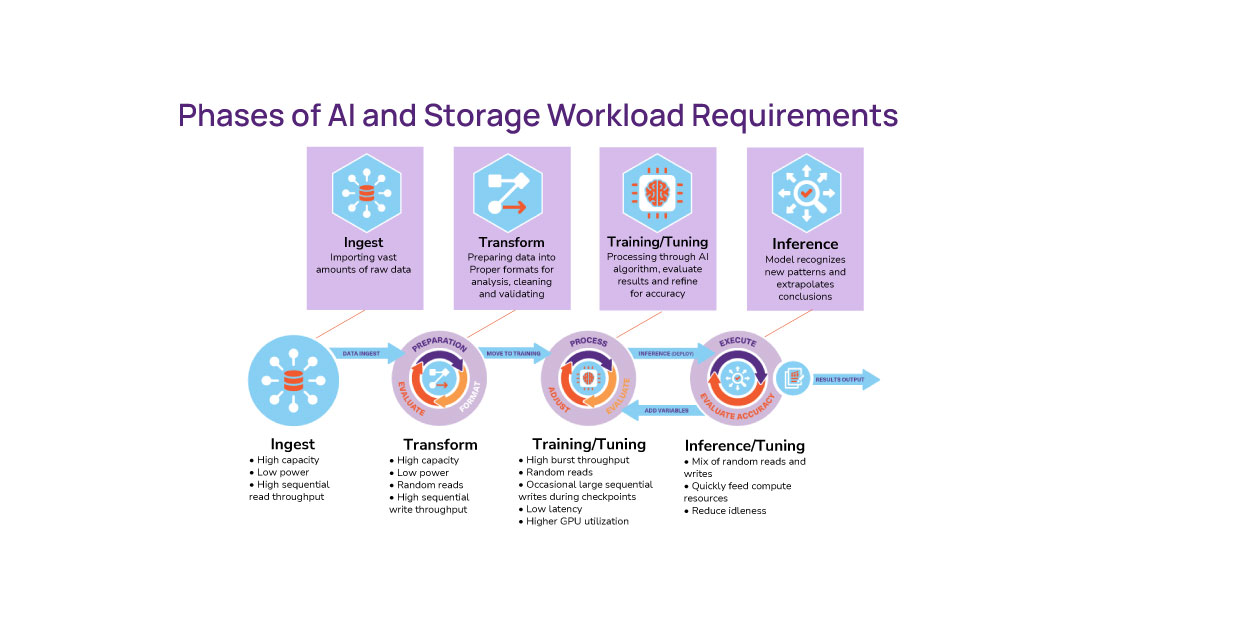






How are Compute Express Link (CXL) and the SNIA Smart Data Accelerator Interface (SDXI) related? It’s a topic we covered in detail at our recent SNIA Networking Storage Forum webcast, “What’s in a Name? Memory Semantics and Data Movement with CXL and SDXI” where our experts, Rita Gupta and Shyam Iyer, introduced both SDXI and CXL, highlighted the benefits of each, discussed data movement needs in a CXL ecosystem and covered SDXI advantages in a CXL interconnect. If you missed the live session, it is available in the SNIA Educational Library along with the presentation slides. The session was highly rated by the live audience who asked several interesting questions. Here are answers to them from our presenters Rita and Shyam.
Q. Now that SDXI v1.0 is out, can application
implementations use SDXI today?
A. Yes. Now that SDXI v1.0 is out, implementations can start building to the v1.0 SNIA standard. If you are looking to influence a future version of the specification, please consider joining the SDXI Technical Working Group (TWG) in SNIA. We are now in the planning process for post v1.0 features so we welcome all new members and implementors to come participate in this new phase of development. Additionally, you can use the SNIA feedback portal to provide your comments.
Q. You mentioned SDXI is
interconnect-agnostic and yet we are talking about SDXI and a specific
interconnect here i.e. CXL. Is SDXI architected to work on CXL?
A. SDXI is designed to be interconnect agnostic. It standardizes
the memory structures, function setup, control, etc. to make sure that a
standardized mover can have an architected global state. It does not preclude
an implementation from taking advantage of the features of an underlying interconnect.
CXL will be an important instance which is why it was a big part of this
presentation.
Q. I think you covered it in the talk,
but can you highlight some specific advantages for SDXI in a CXL environment
and some ways CXL can benefit from an SDXI standardized data mover?
A. CXL-enabled architecture expands the
targetable System Memory space for an architected memory data mover like SDXI. Also,
as I explained, SDXI implementors have a few unique implementation choices in a
CXL-based architecture that can further improve/optimize data movement. So,
while SDXI is interconnect agnostic, SDXI and CXL can be great buddies :-).
With CXL concepts like “shared memory”
and “pooled memory,” SDXI can now become a multi-host data mover. This is huge
because it eliminates a lot of software stack layers to perform both intra-host
and inter-host bulk data transfers.
Q. CXL is termed as low latency, what are
the latency targets for CXL devices?
A. While overall CXL device latency
targets may depend on the media, the guidance is to have CXL access latency to
be within one NUMA hop. In other words, the CXL memory access should have
similar latency to that of remote socket DRAM access.
Q. How are SNIA and CXL collaborating on
this?
A. SNIA and CXL have a marketing alliance
agreement that allows SNIA and CXL to work on joint marketing activities such
as this webcast to promote collaborative work. In addition, many of the
contributing companies are members of both CXL and the SNIA SDXI TWG. This
helps in ensuring the two groups stay connected.
Q. What is the difference in memory
pooling and memory sharing? What are the advantages of either?
A. Memory pooling (also referred to as memory disaggregation) is an approach where multiple hosts allocate dedicated memory resources from the pool of CXL memory device(s) dynamically, as needed. The memory resources are allocated to one host at any given time. The technique ensures optimum and efficient usage of expensive memory resources, providing TCO advantage.
In a memory sharing usage model,
allocated blocks of memory can be used by multiple hosts at the same time. The
memory sharing provides optimum usage of memory resources and also provides
efficiency on memory allocation and management.
Q. CXL is termed as low latency, what are
the latency targets for CXL devices? Can SDXI enable the data movement across
the CXL devices in peer-to-peer fashion?
A. Yes. Indeed. SDXI devices can target
all memory regions accessible to the host and among other usage models perform data
movement across CXL devices in a peer-to-peer fashion. Of course, this assumes
a few implications around platform support, but SDXI is designed for such data
movement use cases as well.
Q. Trying to look for equivalent
terms…can you think of SDXI as what NVMe® is for NVMe-oF and CXL as the
underlying transport fabric like TCP?
A. There are some similarities, but the use
cases are very different and therefore I suspect the implementations would
drive the development of these standards very differently. Like NVMe which
defines various opcodes to perform storage operations, SDXI defines various
opcodes to perform memory operations. And it is also true that SDXI opcodes/descriptors
can be used to move data using PCIe and CXL as the I/O interconnect and a future
expansion to ethernet based interconnects can be envisioned. Having said that,
memory operations have different SLAs, performance characteristics, byte
addressability concerns, and ordering requirements among other things. SDXI is
enabling a new class of such devices.
Q. Is there a limitation on the
granularity size of transfer – SDXI is limited to bulk transfers only or does
it also address small granular transfers?
A. As a standard specification, SDXI allows
implementations to process descriptors for data transfer sizes ranging from 1 Byte
to 4GB. That said, the software may use size thresholds to determine offloading
data transfers via SDXI devices based on implementation quality.
Q. Will there be a standard SDXI driver
available from SNIA or is each company responsible for building a driver to be
compatible with the SDXI compatible hardware they build?
A. The SDXI TWG is not developing
the common open-source driver because of license considerations in SNIA. The
SDXI TWG is beginning to work on a common user-space open-source library for
applications.
The SDXI spec is enabling the development
of a common class level driver by reserving a class code with PCI SIG for PCIe
based implementations. The driver implementations are being enabled and
influenced with discussions in the SDXI TWG and other forums.
Q. Software development is throttled by
the availability of standard CXL host platforms. When will those be available and
for what versions?
A. We cannot comment on specific
product/platform availability and would advise to connect with the vendors for
the same. There is CXL1.1 based host platform available in the market and
publicly announced.
Q. Does a PCIe based data mover with an
SDXI interface actually DMA data across the PCIe link? If so, isn’t this higher latency and less
power efficient than a memcpy operation?
A. There is quite a bit of prior art
research within academia and industry that indicates that for certain data
transfer size thresholds, an offloaded data movement device like an SDXI device
can be more performant than employing a CPU thread. While software can employ
more CPU threads to do the same operation via memcpy it comes at a cost. By
offloading them to SDXI devices, expensive CPU threads can be used for other
computational tasks helping improve overall TCO. Certainly, this will depend on
implementation quality, but SDXI is enabling such innovations with a
standardized framework.
Q. Will SDXI impact/change/unify NVMe?
A. SDXI is expected to complement the data
movement and acceleration needs of systems comprising NVMe devices as well as
needs within an NVMe subsystem to improve storage performance. In fact, SNIA
has created a subgroup, the “CS+SDXI” subgroup that is comprised of members of SNIA’s Computational
Storage TWG and SDXI TWG to think about such kinds
of use cases. Many computational storage use cases can be enhanced with a
combination of NVMe and SDXI-enabled technologies.
(CXL) and the SNIA Smart Data Accelerator Interface (SDXI) related? It’s a topic we covered in detail at our recent SNIA Networking Storage Forum webcast, “What’s in a Name? Memory Semantics and Data Movement with CXL and SDXI” where our experts, Rita Gupta and Shyam Iyer, introduced both SDXI and CXL, highlighted the benefits of each, discussed data movement needs in a CXL ecosystem and covered SDXI advantages in a CXL interconnect. If you missed the live session, it is available in the SNIA Educational Library along with the presentation slides. The session was highly rated by the live audience who asked several interesting questions. Here are answers to them from our presenters Rita and Shyam.
Q. Now that SDXI v1.0 is out, can application
implementations use SDXI today?
A. Yes. Now that SDXI v1.0 is out, implementations can start building to the v1.0 SNIA standard. If you are looking to influence a future version of the specification, please consider joining the SDXI Technical Working Group (TWG) in SNIA. We are now in the planning process for post v1.0 features so we welcome all new members and implementors to come participate in this new phase of development. Additionally, you can use the SNIA feedback portal to provide your comments.
Q. You mentioned SDXI is
interconnect-agnostic and yet we are talking about SDXI and a specific
interconnect here i.e. CXL. Is SDXI architected to work on CXL?
A. SDXI is designed to be interconnect agnostic. It standardizes
the memory structures, function setup, control, etc. to make sure that a
standardized mover can have an architected global state. It does not preclude
an implementation from taking advantage of the features of an underlying interconnect.
CXL will be an important instance which is why it was a big part of this
presentation.
Q. I think you covered it in the talk,
but can you highlight some specific advantages for SDXI in a CXL environment
and some ways CXL can benefit from an SDXI standardized data mover?
A. CXL-enabled architecture expands the
targetable System Memory space for an architected memory data mover like SDXI. Also,
as I explained, SDXI implementors have a few unique implementation choices in a
CXL-based architecture that can further improve/optimize data movement. So,
while SDXI is interconnect agnostic, SDXI and CXL can be great buddies :-).
With CXL concepts like “shared memory”
and “pooled memory,” SDXI can now become a multi-host data mover. This is huge
because it eliminates a lot of software stack layers to perform both intra-host
and inter-host bulk data transfers.
Q. CXL is termed as low latency, what are
the latency targets for CXL devices?
A. While overall CXL device latency
targets may depend on the media, the guidance is to have CXL access latency to
be within one NUMA hop. In other words, the CXL memory access should have
similar latency to that of remote socket DRAM access.
Q. How are SNIA and CXL collaborating on
this?
A. SNIA and CXL have a marketing alliance
agreement that allows SNIA and CXL to work on joint marketing activities such
as this webcast to promote collaborative work. In addition, many of the
contributing companies are members of both CXL and the SNIA SDXI TWG. This
helps in ensuring the two groups stay connected.
Q. What is the difference in memory
pooling and memory sharing? What are the advantages of either?
A. Memory pooling (also referred to as memory disaggregation) is an approach where multiple hosts allocate dedicated memory resources from the pool of CXL memory device(s) dynamically, as needed. The memory resources are allocated to one host at any given time. The technique ensures optimum and efficient usage of expensive memory resources, providing TCO advantage.
In a memory sharing usage model,
allocated blocks of memory can be used by multiple hosts at the same time. The
memory sharing provides optimum usage of memory resources and also provides
efficiency on memory allocation and management.
Q. CXL is termed as low latency, what are
the latency targets for CXL devices? Can SDXI enable the data movement across
the CXL devices in peer-to-peer fashion?
A. Yes. Indeed. SDXI devices can target
all memory regions accessible to the host and among other usage models perform data
movement across CXL devices in a peer-to-peer fashion. Of course, this assumes
a few implications around platform support, but SDXI is designed for such data
movement use cases as well.
Q. Trying to look for equivalent
terms…can you think of SDXI as what NVMe® is for NVMe-oF and CXL as the
underlying transport fabric like TCP?
A. There are some similarities, but the use
cases are very different and therefore I suspect the implementations would
drive the development of these standards very differently. Like NVMe which
defines various opcodes to perform storage operations, SDXI defines various
opcodes to perform memory operations. And it is also true that SDXI opcodes/descriptors
can be used to move data using PCIe and CXL as the I/O interconnect and a future
expansion to ethernet based interconnects can be envisioned. Having said that,
memory operations have different SLAs, performance characteristics, byte
addressability concerns, and ordering requirements among other things. SDXI is
enabling a new class of such devices.
Q. Is there a limitation on the
granularity size of transfer – SDXI is limited to bulk transfers only or does
it also address small granular transfers?
A. As a standard specification, SDXI allows
implementations to process descriptors for data transfer sizes ranging from 1 Byte
to 4GB. That said, the software may use size thresholds to determine offloading
data transfers via SDXI devices based on implementation quality.
Q. Will there be a standard SDXI driver
available from SNIA or is each company responsible for building a driver to be
compatible with the SDXI compatible hardware they build?
A. The SDXI TWG is not developing
the common open-source driver because of license considerations in SNIA. The
SDXI TWG is beginning to work on a common user-space open-source library for
applications.
The SDXI spec is enabling the development
of a common class level driver by reserving a class code with PCI SIG for PCIe
based implementations. The driver implementations are being enabled and
influenced with discussions in the SDXI TWG and other forums.
Q. Software development is throttled by
the availability of standard CXL host platforms. When will those be available and
for what versions?
A. We cannot comment on specific
product/platform availability and would advise to connect with the vendors for
the same. There is CXL1.1 based host platform available in the market and
publicly announced.
Q. Does a PCIe based data mover with an
SDXI interface actually DMA data across the PCIe link? If so, isn’t this higher latency and less
power efficient than a memcpy operation?
A. There is quite a bit of prior art
research within academia and industry that indicates that for certain data
transfer size thresholds, an offloaded data movement device like an SDXI device
can be more performant than employing a CPU thread. While software can employ
more CPU threads to do the same operation via memcpy it comes at a cost. By
offloading them to SDXI devices, expensive CPU threads can be used for other
computational tasks helping improve overall TCO. Certainly, this will depend on
implementation quality, but SDXI is enabling such innovations with a
standardized framework.
Q. Will SDXI impact/change/unify NVMe?
A. SDXI is expected to complement the data
movement and acceleration needs of systems comprising NVMe devices as well as
needs within an NVMe subsystem to improve storage performance. In fact, SNIA
has created a subgroup, the “CS+SDXI” subgroup that is comprised of members of SNIA’s Computational
Storage TWG and SDXI TWG to think about such kinds
of use cases. Many computational storage use cases can be enhanced with a
combination of NVMe and SDXI-enabled technologies.
(CXL) and the SNIA Smart Data Accelerator Interface (SDXI) related? It’s a topic we covered in detail at our recent SNIA Networking Storage Forum webcast, “What’s in a Name? Memory Semantics and Data Movement with CXL and SDXI” where our experts, Rita Gupta and Shyam Iyer, introduced both SDXI and CXL, highlighted the benefits of each, discussed data movement needs in a CXL ecosystem and covered SDXI advantages in a CXL interconnect. If you missed the live session, it is available in the SNIA Educational Library along with the presentation slides. The session was highly rated by the live audience who asked several interesting questions. Here are answers to them from our presenters Rita and Shyam.
Q. Now that SDXI v1.0 is out, can application
implementations use SDXI today?
A. Yes. Now that SDXI v1.0 is out, implementations can start building to the v1.0 SNIA standard. If you are looking to influence a future version of the specification, please consider joining the SDXI Technical Working Group (TWG) in SNIA. We are now in the planning process for post v1.0 features so we welcome all new members and implementors to come participate in this new phase of development. Additionally, you can use the SNIA feedback portal to provide your comments.
Q. You mentioned SDXI is
interconnect-agnostic and yet we are talking about SDXI and a specific
interconnect here i.e. CXL. Is SDXI architected to work on CXL?
A. SDXI is designed to be interconnect agnostic. It standardizes
the memory structures, function setup, control, etc. to make sure that a
standardized mover can have an architected global state. It does not preclude
an implementation from taking advantage of the features of an underlying interconnect.
CXL will be an important instance which is why it was a big part of this
presentation.
Q. I think you covered it in the talk,
but can you highlight some specific advantages for SDXI in a CXL environment
and some ways CXL can benefit from an SDXI standardized data mover?
A. CXL-enabled architecture expands the
targetable System Memory space for an architected memory data mover like SDXI. Also,
as I explained, SDXI implementors have a few unique implementation choices in a
CXL-based architecture that can further improve/optimize data movement. So,
while SDXI is interconnect agnostic, SDXI and CXL can be great buddies :-).
With CXL concepts like “shared memory”
and “pooled memory,” SDXI can now become a multi-host data mover. This is huge
because it eliminates a lot of software stack layers to perform both intra-host
and inter-host bulk data transfers.
Q. CXL is termed as low latency, what are
the latency targets for CXL devices?
A. While overall CXL device latency
targets may depend on the media, the guidance is to have CXL access latency to
be within one NUMA hop. In other words, the CXL memory access should have
similar latency to that of remote socket DRAM access.
Q. How are SNIA and CXL collaborating on
this?
A. SNIA and CXL have a marketing alliance
agreement that allows SNIA and CXL to work on joint marketing activities such
as this webcast to promote collaborative work. In addition, many of the
contributing companies are members of both CXL and the SNIA SDXI TWG. This
helps in ensuring the two groups stay connected.
Q. What is the difference in memory
pooling and memory sharing? What are the advantages of either?
A. Memory pooling (also referred to as memory disaggregation) is an approach where multiple hosts allocate dedicated memory resources from the pool of CXL memory device(s) dynamically, as needed. The memory resources are allocated to one host at any given time. The technique ensures optimum and efficient usage of expensive memory resources, providing TCO advantage.
In a memory sharing usage model,
allocated blocks of memory can be used by multiple hosts at the same time. The
memory sharing provides optimum usage of memory resources and also provides
efficiency on memory allocation and management.
Q. CXL is termed as low latency, what are
the latency targets for CXL devices? Can SDXI enable the data movement across
the CXL devices in peer-to-peer fashion?
A. Yes. Indeed. SDXI devices can target
all memory regions accessible to the host and among other usage models perform data
movement across CXL devices in a peer-to-peer fashion. Of course, this assumes
a few implications around platform support, but SDXI is designed for such data
movement use cases as well.
Q. Trying to look for equivalent
terms…can you think of SDXI as what NVMe® is for NVMe-oF and CXL as the
underlying transport fabric like TCP?
A. There are some similarities, but the use
cases are very different and therefore I suspect the implementations would
drive the development of these standards very differently. Like NVMe which
defines various opcodes to perform storage operations, SDXI defines various
opcodes to perform memory operations. And it is also true that SDXI opcodes/descriptors
can be used to move data using PCIe and CXL as the I/O interconnect and a future
expansion to ethernet based interconnects can be envisioned. Having said that,
memory operations have different SLAs, performance characteristics, byte
addressability concerns, and ordering requirements among other things. SDXI is
enabling a new class of such devices.
Q. Is there a limitation on the
granularity size of transfer – SDXI is limited to bulk transfers only or does
it also address small granular transfers?
A. As a standard specification, SDXI allows
implementations to process descriptors for data transfer sizes ranging from 1 Byte
to 4GB. That said, the software may use size thresholds to determine offloading
data transfers via SDXI devices based on implementation quality.
Q. Will there be a standard SDXI driver
available from SNIA or is each company responsible for building a driver to be
compatible with the SDXI compatible hardware they build?
A. The SDXI TWG is not developing
the common open-source driver because of license considerations in SNIA. The
SDXI TWG is beginning to work on a common user-space open-source library for
applications.
The SDXI spec is enabling the development
of a common class level driver by reserving a class code with PCI SIG for PCIe
based implementations. The driver implementations are being enabled and
influenced with discussions in the SDXI TWG and other forums.
Q. Software development is throttled by
the availability of standard CXL host platforms. When will those be available and
for what versions?
A. We cannot comment on specific
product/platform availability and would advise to connect with the vendors for
the same. There is CXL1.1 based host platform available in the market and
publicly announced.
Q. Does a PCIe based data mover with an
SDXI interface actually DMA data across the PCIe link? If so, isn’t this higher latency and less
power efficient than a memcpy operation?
A. There is quite a bit of prior art
research within academia and industry that indicates that for certain data
transfer size thresholds, an offloaded data movement device like an SDXI device
can be more performant than employing a CPU thread. While software can employ
more CPU threads to do the same operation via memcpy it comes at a cost. By
offloading them to SDXI devices, expensive CPU threads can be used for other
computational tasks helping improve overall TCO. Certainly, this will depend on
implementation quality, but SDXI is enabling such innovations with a
standardized framework.
Q. Will SDXI impact/change/unify NVMe?
A. SDXI is expected to complement the data
movement and acceleration needs of systems comprising NVMe devices as well as
needs within an NVMe subsystem to improve storage performance. In fact, SNIA
has created a subgroup, the “CS+SDXI” subgroup that is comprised of members of SNIA’s Computational
Storage TWG and SDXI TWG to think about such kinds
of use cases. Many computational storage use cases can be enhanced with a
combination of NVMe and SDXI-enabled technologies.
Leave a Reply