

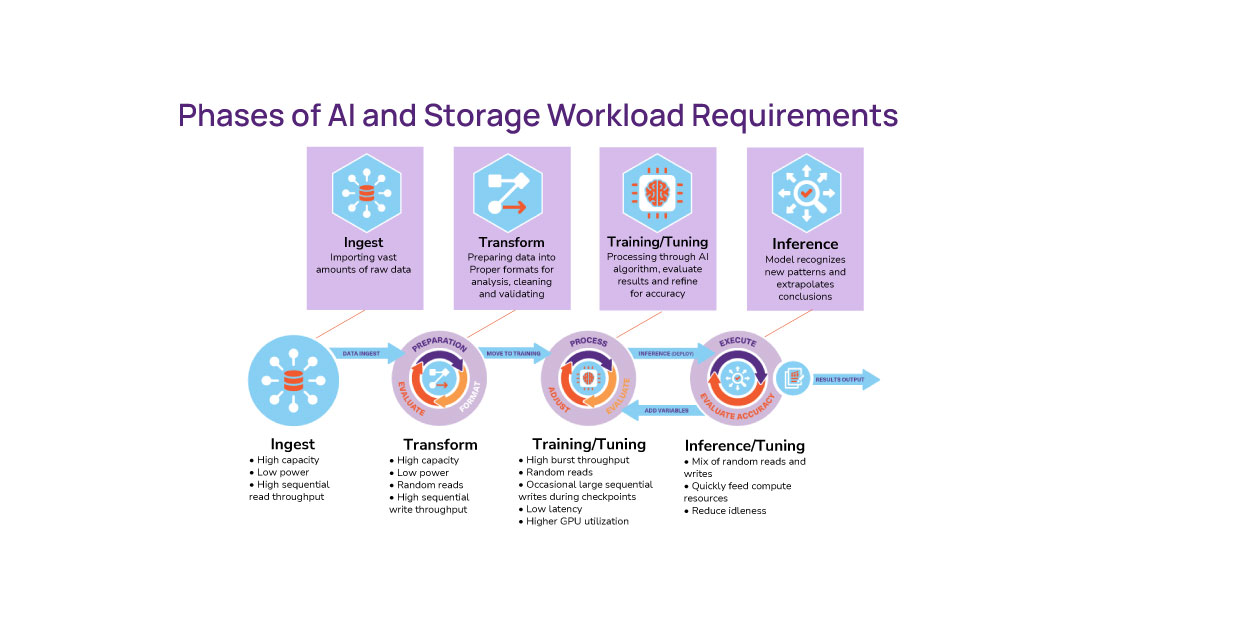




The SNIA Networking
Storage Forum recently
hosted another webcast in our
Great
Storage Debate webcast series. This time, our SNIA experts debated three competing
visions about how storage should be done: Hyperconverged Infrastructure (HCI),
Disaggregated Storage, and Centralized Storage. If you missed the live event,
it’s available
on-demand. Questions
from the webcast attendees made the panel debate quite lively. As promised,
here are answers to those questions.
Q. Can you imagine a realistic scenario where the different storage
types are used as storage tiers? How much are they interoperable?
A. Most HCI solutions already have a tiering/caching structure
built-in. However, a user could use HCI
for hot to warm data, and also tier less frequently accessed data out to a separate
backup/archive. Some of the HCI
solutions have close partnerships with backup/archive vendor solutions just for
this purpose.
Q. Does Hyperconverged (HCI) use primarily object storage with
erasure coding for managing the distributed storage, such as vSAN for VxRail
(from Dell)?
A. That is accurate for vSAN, but
other HCI solutions are not necessarily object based. Even if object-based, the
object interface is rarely exposed. Erasure coding is a common method of
distributing the data across the cluster for increased durability with
efficient space sharing.
Q. Is there a possibility if two or more classification of storage can
co-exist or deployed? Examples please?
A. Often IT organizations have
multiple types of storage deployed in their data centers, particularly over
time with various types of legacy systems. Also, HCI solutions that support
iSCSI can interface with these legacy systems to enable better sharing of data
to avoid silos.
Q. How would you classify HPC
deployment given it is more distributed file systems and converged storage?
does it need a new classification?
A. Often HPC storage is deployed
on large, distributed file systems (e.g. Lustre), which I would classify as
distributed, scale-out storage, but not hyperconverged, as the compute is still
on separate servers.
Q. A lot of HCI solutions are
already allowing heterogeneous nodes within a cluster. What about these
“new” Disaggregated HCI solutions that uses “traditional”
storage arrays in the solution (thus not using a Software Defined Storage
solution? Doesn’t it sound a step back? It seems most of the innovation comes
on the software.
A. The solutions marketed as
disaggregated HCI are not HCI. They are traditional servers and storage
combined in a chassis. This would meet
the definition of converged, but not hyperconverged.
Q. Why is HCI growing so quickly
and seems so popular of late? It seems
to be one of the fastest growing “data storage” use cases.
A. HCI has many advantages, as I
shared in the slides up front. The #1 reason for the growth and popularity is
the ease of deployment and management.
Any IT person who is familiar with deploying and managing a VM can now
easily deploy and manage the storage with the VM. No specialized storage system skillsets
required, which makes better use of limited IT people resources, and reduces
OpEx.
Q. Where do you categorize newer
deployments like Vast Data? Is that considered NAS since it presents as NFS and
CIFS?
A. I would categorize Vast Data as
scale-out, software-defined storage. HCI
is also a type of scale-out, software-defined storage, but with compute as
well, so that is the key difference.
Q. So what happens when HCI works
with ANY storage including centralized solutions. What is HCI then?
A. I believe this question is
referencing the SCSi interface support.
HCI solutions that support iSCSI can interface with other types of
storage systems to enable better sharing of data to avoid silos.
Q. With NVMe/RoCE becoming more
available, DAS-like performance while have reducing CPU usage on the hosts
massively, saving license costs (potentially, we are only in pilot phase) does
the ball swing back towards disaggregated?
A. I’m not sure I fully understand
the question, but RDMA can be used to streamline the inter-node traffic across
the HCI cluster. Network performance
becomes more critical as the size of the cluster, and therefore the traffic
between nodes increases, and RDMA can reduce any network bottlenecks. RoCEv2 is
popular, and some HCI solutions also support iWARP. Therefore, as HCI solutions adopt RDMA, this
is not a driver to disaggregated.
Q. HCI was initially targeted at
SMB and had difficulty scaling beyond 16 nodes. Why would HCI be the choice for
large scale enterprise implementations?
A. HCI has proven itself as
capable of running a broad range of workloads in small to large data center
environments at this point. Each HCI solution can scale to different numbers of
nodes, but usage data shows that single clusters rarely exceed about 12 nodes,
and then users start a new cluster.
There are a mix of reasons for this:
concerns about the size of failure domains, departmental or remote site
deployment size requirements, but often it’s the software license fees for the
applications running on the HCI infrastructure that limits the typical clusters
sizes in practice.
Q. SPC (Storage Performance
Council) benchmarks are still the gold standard (maybe?) and my understanding
is they typically use an FC SAN. Is that changing? I understand that the
underlying hardware is what determines performance but I’m not aware of SPC
benchmarks using anything other than SAN.
A. Myriad benchmarks are used to
measure HCI performance across a cluster. I/O benchmarks that are variants on
FIO are common to measure the storage performance, and then the compute
performance is often measured using other benchmarks, such as TPC benchmarks
for database performance, LoginVSI for VDI performance, etc.
Q. What is the current
implementation mix ratio in the industry? What is the long-term projected mix
ratio?
A. Today the enterprise is
dominated by centralized storage with HCI in second place and growing more
rapidly. Large cloud service providers and hyperscalers are dominated by
disaggregated storage, but also use some centralized storage and some have
their own customized HCI implementations for specific workloads. HPC and AI
customers use a mix of disaggregated and centralized storage. In the long-term,
it’s possible that disaggregated will have the largest overall share since
cloud storage is growing the most, with centralized storage and HCI splitting
the rest.
Q. Is the latency high for HCI vs.
disaggregated vs. centralized?
A. It depends on the implementation.
HCI and disaggregated might have slightly higher latency than centralized
storage if they distribute writes across nodes before acknowledging them or if
they must retrieve reads from multiple nodes. But HCI and disaggregated storage
can also be implemented in a way that offers the same latency as centralized.
Q. What about GPUDirect?
A. GPUDirect Storage allows GPUs
to access storage more directly to reduce latency. Currently it is supported by
some types of centralized and disaggregated storage. In the future, it might be
supported with HCI as well.
Q. Splitting so many hairs here.
Each of the three storage types are more about HOW the storage is consumed by
the user/application versus the actual architecture.
A. Yes, that is largely correct,
but the storage architecture can also affect how it’s consumed.
Q. Besides technical qualities, is
there a financial differentiator between solutions? For example, OpEx and
CapEx, ROI?
A. For very large-scale storage
implementations, disaggregated generally has the lowest CapEx and OpEx because
the higher initial cost of managing distributed storage software is amortized
across many nodes and many terabytes. For medium to large implementations,
centralized storage usually has the best CapEx and OpEx. For small to medium
implementations, HCI usually has the lowest CapEx and OpEx because it’s easy
and fast to acquire and deploy. However, it always depends on the specific type
of storage and the skill set or expertise of the team managing the storage.
Q. Why wouldn’t disaggregating
storage compute and memory be the next trend? The Hyperscalers have already
done it. What are we waiting for?
A. Disaggregating compute is
indeed happening, supported by VMs, containers, and faster network links.
However, disaggregating memory across different physical machines is more
challenging because even today’s very fast network links have much higher latency
than memory. For now, memory disaggregation is largely limited to being done
“inside the box” or within one rack with links like PCIe, or to cases
where the compute and memory stick together and are disaggregated as a unit.
Q. Storage lends itself as first
choice for disaggregation as mentioned before. What about disaggregation of
other resources (such as networking, GPU, memory) in the future and how do you
believe will it impact the selection of centralized vs disaggregated storage?
Will Ethernet stay 1st choice for the fabric for disaggregation?
A. See the above answer about
disaggregating memory. Networking can be disaggregated within a rack by using a
very low-latency fabric, for example PCIe, but usually networking is used to
support disaggregation of other resources. GPUs can be disaggregated but
normally still travel with some CPU and memory in the same box, though this
could change in the near future. Ethernet will indeed remain the 1st networking
choice for disaggregation, but other network types will also be used
(InfiniBand, Fibre Channel, Ethernet with RDMA, etc.)
Don’t forget
to check out our other great storage debates, including: File vs. Block vs.
Object Storage, Fibre Channel vs. iSCSI, FCoE vs. iSCSI vs. iSER, RoCE vs.
iWARP, and Centralized vs. Distributed. You can view them all on our SNIAVideo
YouTube Channel.

SNIA Developer Conference September 15-17, 2025 | Santa Clara, CA




Featured Post

CXL
April 22 2025
Unlocking CXL's Potential Q&A
Data Storage
April 14 2025
SNIA: Experts on Data Explained

Ceph
April 1 2025
Leave a Reply