
 SNIA Developer Conference September 15-17, 2025 | Santa Clara, CA
SNIA Developer Conference September 15-17, 2025 | Santa Clara, CA







 by Arthur Sainio, SNIA NVDIMM SIG Co-Chair, SMART Modular
SNIA’s Non-Volatile DIMM (NVDIMM) Special Interest Group (SIG) had a tremendous response to their most recent webcast: NVDIMM: Applications are
by Arthur Sainio, SNIA NVDIMM SIG Co-Chair, SMART Modular
SNIA’s Non-Volatile DIMM (NVDIMM) Special Interest Group (SIG) had a tremendous response to their most recent webcast: NVDIMM: Applications are Here! You can view the webcast on demand.
Viewers had many questions during the webcast. In this blog, the NVDIMM SIG answers those questions and shares the SIG’s knowledge of NVDIMM technology.
Have a question? Send it to nvdimmsigchair@snia.org.
1. What about 3DXpoint, how will this technology impact the market?
3DXPoint DIMMs will likely have a significant impact on the market. They are fast enough to use as a slower tier of memory between NAND and DRAM. It is still too early to tell though.
2. What are good benchmark tools for DAX and what are the differences between NVML applications and DAX aware applications?
For benchmark tools, please see the answer for (11).
NVML applications are written specifically for NVM (Non-Volatile Memory). They may use the open source NVML libraries (http://pmem.io/nvml) for their usage.
DAX is a File System feature that avoids the usage of Page Cache buffers. DAX aware applications are aware that the writes and reads would go directly to the underlying NVM without being cached.
3. On the slide talking about NUMA, there was a mention accessing NVDIMMs from a CPU on a different memory bus. The part about larger access times was clear enough. However, I came away with the impression that there is a correctness issue with handling of ADR signal as well. Please clarify.
If this question is asking whether the NUMA remote CPU will successfully flush ADR-protected buffers to memory connected to the NUMA near CPU then yes there is the potential for a problem in this area. However ADR is an Intel feature that is not specified in the JEDEC NVDIMM standard, so this is an Intel specific implementation question. The question needs to be posed to Intel.
4. How common is NVDIMM compatible BIOS? How would one check?
They are becoming more common all the time. There are at least 8 server/storage systems from Intel and 22 from Supermicro that support NVDIMMs. Several other motherboard vendors have systems that support NVDIMMs. Most of the NVDIMM vendors have the lists posted on their websites.
5. How does a system go in to save? How what exactly does the BIOS have to do to get a system before asserting save?
The BIOS does the initial checking of making sure the NVDIMM has backup supply on power loss, before it ARMs it. Also, the BIOS makes sure that any RESTORE of the previously saved data is properly done. This involves a set of operations by setting appropriate registers in the NVDIMM module – all that happens during the boot up initialization. On A/C Power Loss, the PCH (Platform Control Hub) detects the condition and initiates what is called the ADR (Asynchronous DRAM Refresh) sequence, terminating in the assertion of SAVE signal by the CPLD. Without the BIOS ARM-ing the NVDIMM module, the NVDIMM module will not respond to the SAVE signal on power loss situation.
6. Could you paint the picture of hardware costs at this point? How soon will NVDIMM-enabled systems be able to become “the rest of us”?
The NVDIMM use DRAM, NAND Flash, a controller and well as many other parts in addition to what are used on standard RDIMMs. On that basis the cost of NVDIMM-N is higher that standard RDIMMs. NVDIMM-enabled systems have been available for several years and are shipping now.
7. Does RHEL 7.3 easily support Linux Kernel 4.4?
RHEL 7.3 is still using the 3.10 version of the Linux Kernel. For RHEL related information, please, check with Red Hat.
You can also refer to: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/7.3_Release_Notes/index.html
The distribution has drivers to support the persistent memory. They have also packaged the libraries for the persistent memory.
8. What are the usual sizes for NVDIMMs available today?
4GB, 8GB, 16GB, 32GB
9. Are there any case studies of each of the NVDIMM-N applications mentioned?
You can find some examples of case studies at these websites: https://channel9.msdn.com/events/build/2016/p466 and https://msdn.com/events/build/2016/p470
10. What is the difference between pmem lib/pmfs in Linux and an DAX enabled files system (like ext-DAX)?
A DAX based File System avoids the usage of Kernel Page Cache Layer for caching its write data. This would make all its write operations go directly to the underlying storage unit. One important thing to understand is, a DAX File System can still use BLOCK DRIVERS for accessing its underlying storage.
PMFS is a File System that is optimized to use Persistent Memory, by completely avoiding the Page Cache and the Block Drivers. It is designed to provide efficient access to Persistent Memory that would be directly accessible via CPU load/store instructions.
Refer to this link: https://github.com/linux-pmfs/pmfs for more details. PMFS, as of now is only in experimental stages.
11. What tool is used to measure the performance?
The performance measurement depends on what kind of Application workload is to be characterized. This is a very complex topic. No single benchmarking tool is good for all the workload characteristics.
For File System performance, SpecFS, Bonnie++, IOZone, FFSB, FileBench etc., are good tools.
SysBench is good for a variety of performance measurements.
Phoronix Test Suite (http://www.phoronix.com/scan.php?page=home) has a variety of tools for Linux based performance measurements.
12. How similar do you expect the OS support for P to be to this support for –N? I don’t see a lot of need for differences at this level (though there certainly will be differences in the BIOS).
As of now, the open source libraries (http://pmem.io) are designed to be agnostic about the underlying memory types. They are simply classified as Persistent Memory, meaning, it could be “-N” or “-P” or something else. The libraries are written for User Space, and they assume that any underlying Kernel support should be transparent.
The “-P” type has been thought of supporting both the DRAM and the PERSISTENT access at the same time. This might need a separate set of drivers in the Kernel.
13. Does the PM-based file system appear to be block addressable from the Application?
A File System creates a layer of virtualization to support the logical entities such as VOLUMES, DIRECTORIES and FILES. Typically, an Application that is running in the User Space has no knowledge of the underlying mechanisms used by a File System for accessing its storage units such as the Persistent Memory. The access provided by a File System to an Application is typically a POSIX File System interface such as open, close, read, write, seek, etc.,
14. Is ADR a pin?
ADR stands for Asynchronous DRAM Refresh. ADR is a feature supported on Intel chipsets that triggers a hardware interrupt to the memory controller which will flush the write-protected data buffers and place the DRAM in self-refresh. This process is critical during a power loss event or system crash to ensure the data is in a “safe” state when the NVDIMM takes control of the DRAM to backup to Flash. Note that ADR does not flush the processor cache. In order to do so, an NMI routine would need to be executed prior to ADR.
Here! You can view the webcast on demand.
Viewers had many questions during the webcast. In this blog, the NVDIMM SIG answers those questions and shares the SIG’s knowledge of NVDIMM technology.
Have a question? Send it to nvdimmsigchair@snia.org.
1. What about 3DXpoint, how will this technology impact the market?
3DXPoint DIMMs will likely have a significant impact on the market. They are fast enough to use as a slower tier of memory between NAND and DRAM. It is still too early to tell though.
2. What are good benchmark tools for DAX and what are the differences between NVML applications and DAX aware applications?
For benchmark tools, please see the answer for (11).
NVML applications are written specifically for NVM (Non-Volatile Memory). They may use the open source NVML libraries (http://pmem.io/nvml) for their usage.
DAX is a File System feature that avoids the usage of Page Cache buffers. DAX aware applications are aware that the writes and reads would go directly to the underlying NVM without being cached.
3. On the slide talking about NUMA, there was a mention accessing NVDIMMs from a CPU on a different memory bus. The part about larger access times was clear enough. However, I came away with the impression that there is a correctness issue with handling of ADR signal as well. Please clarify.
If this question is asking whether the NUMA remote CPU will successfully flush ADR-protected buffers to memory connected to the NUMA near CPU then yes there is the potential for a problem in this area. However ADR is an Intel feature that is not specified in the JEDEC NVDIMM standard, so this is an Intel specific implementation question. The question needs to be posed to Intel.
4. How common is NVDIMM compatible BIOS? How would one check?
They are becoming more common all the time. There are at least 8 server/storage systems from Intel and 22 from Supermicro that support NVDIMMs. Several other motherboard vendors have systems that support NVDIMMs. Most of the NVDIMM vendors have the lists posted on their websites.
5. How does a system go in to save? How what exactly does the BIOS have to do to get a system before asserting save?
The BIOS does the initial checking of making sure the NVDIMM has backup supply on power loss, before it ARMs it. Also, the BIOS makes sure that any RESTORE of the previously saved data is properly done. This involves a set of operations by setting appropriate registers in the NVDIMM module – all that happens during the boot up initialization. On A/C Power Loss, the PCH (Platform Control Hub) detects the condition and initiates what is called the ADR (Asynchronous DRAM Refresh) sequence, terminating in the assertion of SAVE signal by the CPLD. Without the BIOS ARM-ing the NVDIMM module, the NVDIMM module will not respond to the SAVE signal on power loss situation.
6. Could you paint the picture of hardware costs at this point? How soon will NVDIMM-enabled systems be able to become “the rest of us”?
The NVDIMM use DRAM, NAND Flash, a controller and well as many other parts in addition to what are used on standard RDIMMs. On that basis the cost of NVDIMM-N is higher that standard RDIMMs. NVDIMM-enabled systems have been available for several years and are shipping now.
7. Does RHEL 7.3 easily support Linux Kernel 4.4?
RHEL 7.3 is still using the 3.10 version of the Linux Kernel. For RHEL related information, please, check with Red Hat.
You can also refer to: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/7.3_Release_Notes/index.html
The distribution has drivers to support the persistent memory. They have also packaged the libraries for the persistent memory.
8. What are the usual sizes for NVDIMMs available today?
4GB, 8GB, 16GB, 32GB
9. Are there any case studies of each of the NVDIMM-N applications mentioned?
You can find some examples of case studies at these websites: https://channel9.msdn.com/events/build/2016/p466 and https://msdn.com/events/build/2016/p470
10. What is the difference between pmem lib/pmfs in Linux and an DAX enabled files system (like ext-DAX)?
A DAX based File System avoids the usage of Kernel Page Cache Layer for caching its write data. This would make all its write operations go directly to the underlying storage unit. One important thing to understand is, a DAX File System can still use BLOCK DRIVERS for accessing its underlying storage.
PMFS is a File System that is optimized to use Persistent Memory, by completely avoiding the Page Cache and the Block Drivers. It is designed to provide efficient access to Persistent Memory that would be directly accessible via CPU load/store instructions.
Refer to this link: https://github.com/linux-pmfs/pmfs for more details. PMFS, as of now is only in experimental stages.
11. What tool is used to measure the performance?
The performance measurement depends on what kind of Application workload is to be characterized. This is a very complex topic. No single benchmarking tool is good for all the workload characteristics.
For File System performance, SpecFS, Bonnie++, IOZone, FFSB, FileBench etc., are good tools.
SysBench is good for a variety of performance measurements.
Phoronix Test Suite (http://www.phoronix.com/scan.php?page=home) has a variety of tools for Linux based performance measurements.
12. How similar do you expect the OS support for P to be to this support for –N? I don’t see a lot of need for differences at this level (though there certainly will be differences in the BIOS).
As of now, the open source libraries (http://pmem.io) are designed to be agnostic about the underlying memory types. They are simply classified as Persistent Memory, meaning, it could be “-N” or “-P” or something else. The libraries are written for User Space, and they assume that any underlying Kernel support should be transparent.
The “-P” type has been thought of supporting both the DRAM and the PERSISTENT access at the same time. This might need a separate set of drivers in the Kernel.
13. Does the PM-based file system appear to be block addressable from the Application?
A File System creates a layer of virtualization to support the logical entities such as VOLUMES, DIRECTORIES and FILES. Typically, an Application that is running in the User Space has no knowledge of the underlying mechanisms used by a File System for accessing its storage units such as the Persistent Memory. The access provided by a File System to an Application is typically a POSIX File System interface such as open, close, read, write, seek, etc.,
14. Is ADR a pin?
ADR stands for Asynchronous DRAM Refresh. ADR is a feature supported on Intel chipsets that triggers a hardware interrupt to the memory controller which will flush the write-protected data buffers and place the DRAM in self-refresh. This process is critical during a power loss event or system crash to ensure the data is in a “safe” state when the NVDIMM takes control of the DRAM to backup to Flash. Note that ADR does not flush the processor cache. In order to do so, an NMI routine would need to be executed prior to ADR.

 SNIA is well known for its technology-focused, no vendor-hype conferences, and this one-day event will feature 12 presentations and two panels that will “level set” the discussion, review persistent memory usage, describe applications incorporating PM available today, discuss the infrastructure and implementation, and provide a vision of the “next generation” of persistent memory.
You’ll meet speakers from SNIA member companies Intel, Micron, Microsemi, VMware, Red Hat, Microsoft, AgigA Tech, Western Digital, and Spin Transfer. Live demonstrations of persistent memory solutions will be featured from Summit underwriters Intel and the SNIA Solid State Storage Initiative, and Summit sponsors Microsemi, VMware, AgigA Tech, SMART Modular, and Spin Transfer.
Registration is complimentary but limited -visit
SNIA is well known for its technology-focused, no vendor-hype conferences, and this one-day event will feature 12 presentations and two panels that will “level set” the discussion, review persistent memory usage, describe applications incorporating PM available today, discuss the infrastructure and implementation, and provide a vision of the “next generation” of persistent memory.
You’ll meet speakers from SNIA member companies Intel, Micron, Microsemi, VMware, Red Hat, Microsoft, AgigA Tech, Western Digital, and Spin Transfer. Live demonstrations of persistent memory solutions will be featured from Summit underwriters Intel and the SNIA Solid State Storage Initiative, and Summit sponsors Microsemi, VMware, AgigA Tech, SMART Modular, and Spin Transfer.
Registration is complimentary but limited -visit  c Storage, and SMB3 plugfests; ten Birds-of-a-Feather Sessions, and amazing networking among 450+ attendees. Sessions on NVMe over Fabrics won the title of most attended, but Persistent Memory, Object Storage, and Performance were right behind. Many thanks to SDC 2016 Sponsors, who engaged attendees in exciting technology discussions.
For those not familiar with SDC, this technical industry event is designed for a variety of storage technologists at various levels from developers to architects to product managers and more. And, true to SNIA's commitment to educating the industry on current and future disruptive technologies, SDC content is now available to all - whether you attended or not - for download and viewing.
c Storage, and SMB3 plugfests; ten Birds-of-a-Feather Sessions, and amazing networking among 450+ attendees. Sessions on NVMe over Fabrics won the title of most attended, but Persistent Memory, Object Storage, and Performance were right behind. Many thanks to SDC 2016 Sponsors, who engaged attendees in exciting technology discussions.
For those not familiar with SDC, this technical industry event is designed for a variety of storage technologists at various levels from developers to architects to product managers and more. And, true to SNIA's commitment to educating the industry on current and future disruptive technologies, SDC content is now available to all - whether you attended or not - for download and viewing.
 You'll want to stream keynotes from Citigroup, Toshiba, DSSD, Los Alamos National Labs, Broadcom, Microsemi, and Intel - they're available now on demand on SNIA's YouTube channel,
You'll want to stream keynotes from Citigroup, Toshiba, DSSD, Los Alamos National Labs, Broadcom, Microsemi, and Intel - they're available now on demand on SNIA's YouTube channel,  Mark Carlson is the current Chair of the SNIA Technical Council (TC). Mark has been a SNIA member and volunteer for over 18 years, and also wears many other SNIA hats. Recently, SNIA on Storage sat down with Mark to discuss his first nine months as the TC Chair and his views on the industry.
SNIA on Storage (SoS): Within SNIA, what is the most important activity of the SNIA Technical Council?
Mark Carlson (MC): The SNIA Technical Council works to coordinate and approve the technical work going on within SNIA. This includes both SNIA Architecture (standards) and SNIA Software. The work is conducted within 13 SNIA
Mark Carlson is the current Chair of the SNIA Technical Council (TC). Mark has been a SNIA member and volunteer for over 18 years, and also wears many other SNIA hats. Recently, SNIA on Storage sat down with Mark to discuss his first nine months as the TC Chair and his views on the industry.
SNIA on Storage (SoS): Within SNIA, what is the most important activity of the SNIA Technical Council?
Mark Carlson (MC): The SNIA Technical Council works to coordinate and approve the technical work going on within SNIA. This includes both SNIA Architecture (standards) and SNIA Software. The work is conducted within 13 SNIA  SoS: What has been your focus this first nine months of 2016?
MC: The SNIA Technical Council has overseen a major effort to integrate a new standard organization into SNIA. The creation of the new
SoS: What has been your focus this first nine months of 2016?
MC: The SNIA Technical Council has overseen a major effort to integrate a new standard organization into SNIA. The creation of the new 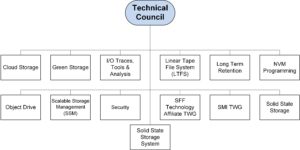 SoS: What's upcoming for the next six months?
MC: The TC is currently working on a white paper to address data center drive requirements and the features and existing interface standards that satisfy some of those requirements. Of course, not all the solutions to these requirements will come from SNIA, but we think SNIA is in a unique position to bring in the data center customers that need these new features and work with the drive vendors to prototype solutions that then make their way into other standards efforts. Features that are targeted at the NVM Express, T10, and T13 committees would be coordinated with these customers.
SoS: Can non-members get involved with SNIA?
MC: Until very recently, if a company wanted to contribute to a software project within SNIA, they had to become a member. This was limiting to the community, and cut off contributions from those who were using the code, so SNIA has developed a convenient
SoS: What's upcoming for the next six months?
MC: The TC is currently working on a white paper to address data center drive requirements and the features and existing interface standards that satisfy some of those requirements. Of course, not all the solutions to these requirements will come from SNIA, but we think SNIA is in a unique position to bring in the data center customers that need these new features and work with the drive vendors to prototype solutions that then make their way into other standards efforts. Features that are targeted at the NVM Express, T10, and T13 committees would be coordinated with these customers.
SoS: Can non-members get involved with SNIA?
MC: Until very recently, if a company wanted to contribute to a software project within SNIA, they had to become a member. This was limiting to the community, and cut off contributions from those who were using the code, so SNIA has developed a convenient 

 can get a "sound bite" of what to expect by downloading SDC podcasts via
can get a "sound bite" of what to expect by downloading SDC podcasts via
Leave a Reply